Ансхул Кундаје сумира своју фрустрацију користећи вештачку интелигенцију у науци у три речи: „Лоши мерило се шири“.
Кундаје истражива рачунска геномија на Универзитету Станфорд у Калифорнији. Жели да укључи било који облик вештачке интелигенције (АИ) који помаже убрзавању напретка у његовом пољу – и безброј истраживача наступило је да понуде алате у ту сврху. Али проналажење оних који најбоље функционишу постају све теже јер неки истраживачи су упитни да захтеве о АИ моделима који су се развили. Ове тврдње могу потрајати месецима да провере. И често се испоставиле да су лажни – углавном зато што су мерила која се користе за демонстрирање и упоређивање перформанси ових алата у сврху не одговарају.
До тада је често прекасно: Кундаје и његове колеге остају играње ударача-кртица након усвојених референтних мерила и „побољшано“ ентузијастичним, али наивним, корисницима. „У међувремену, сви су користили ове (мерило) за све врсте погрешних ствари, а затим имате погрешне информације и погрешна предвиђања тамо“, каже он.

„Још један дубоки тренутак“: Кинески АИ Модел Кими К2 мера узбуђење
Ово је само један разлог зашто се растући број научника брине да све док се немично ради радикално побољша, АИ системи дизајнирани да убрзају напредак у науци имаће супротан ефекат.
Бенцхмарк је тест који се може користити за упоређивање перформанси различитих метода, баш као што стандардна дужина метра даје начин да се процени тачност владара. „То је стандардизација и дефиниција онога што подразумевамо под напретком“, каже Мак Веллинг, истраживач машинског учења и суоснивач Цуспаи, компанија АИ са седиштем у Цамбридгеу, Велика Британија. Добра референтна мерила омогућавају кориснику да одабере најбољу методу за одређену апликацију или да утврди да ли може да пружи више конвенционалних алгоритама бољег резултата. „Али прво питање“, каже Веллинг „, шта мислимо на“ боље „?“
То је изненађујуће дубоко питање. Да ли „боље“ значи брже? Јефтиније? Тачније? Ако купујете аутомобил, мораћете да размотрите широк спектар фактора, попут убрзања, капацитета за покретање и сигурност, сваки са сопственим степеном важности за вас. АИ Бенцхмарк Алати нису различити – за неке апликације, на пример, брзина можда није важна колико тачност, на пример.
Али још је сложеније од тога. Ако је ваш референтни мерило лоше дизајниран, информације које вам даје могу бити погрешни. Ако постоји „цурење“, у којем се вршилац се ослања на податке који су коришћени за обуку алгоритма, мерило постаје више игре меморије него тест решавања проблема. Или тест може бити само небитан према вашим потребама: на пример, то би могло бити претерано специфично, скривајући неспособност система да одговори на широкостепено постављање питања која вас занимају.

Који су најбољи АИ алати за истраживање? Природаводич
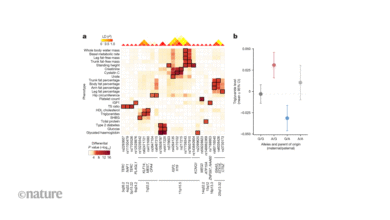
Ово је проблем да су Кундаје и његове колеге идентификовале са моделима ДНК језика (ДНАРМС), који АИ програмери мисле да би могло помоћи откривању занимљивих регулаторних механизама у геном. Око 1,5% људског генома састоји се од секвенци шифрирања протеина који пружају предлошци за стварање РНА (транскрипције) и протеина (превод). Између 5% и 20% генома састоји се од регулаторних елемената који кодирају који координирају транскрипцију гена и превод. Доведите у даљине ДАЛЛМС и они би могли да помогну да тумаче и открију функционалне секвенце, предвиђају последице измене тих секвенци и редизајнирати их да имају специфична, жељена својства.
До сада је, међутим, ДНГРМС-а пропала од ових циљева. Према Кундајама и његовим колегама, то је делом зато што се не користе за праве задатке. Они су дизајнирани да се повољно упореду против референтних тестова, од којих су многе оцењивале корисност не кључним биолошким апликацијама, већ и да сурогат циљеви могу да се сусретну1. Ситуација није за разлику од школа које „подучавају тесту“ – завршите са студентима (или АИ алатом) који су квалификовани да прођу тест, али мало друго.
Кундаје и његове колеге на Станфорд Универзитету нашли су ове кључне недостатке у неколико популарних мјерила ДНГЛМ, скупове података и метрике. На пример, један кључни задатак оцењује способност модела да се рангира функционалне генетске варијанте: промене у ДНК секвенци које могу утицати на ризик од болести или молекуларне функције у ћелијама. Иако су неки далми једноставно не процењивани на овом задатку, други користе погрешне вредности бандера који не желе да објаснемо „повезивање неравнотеже“, не-случајном савезу генетских варијанти.
Због чега је теже изоловати праве функционалне варијанте, мане која даје нереалне процене способности ових модела да утврде такве варијанте. Грешка је нокие, Каже Кундаје. „Ово не захтева дубоко знање о домену – генетика 101.“
Транспарентност и надувавање
Неадекватни референтни мерило стварају сличан проблем у настави до тестирања у низу научних дисциплина. Али неуспеси се не догађају само зато што је изазовно створити добру референтну мјерину: Често је то што нема довољно притиска да боље, према Ницк МцГрееви, који је прошле године на Принцетонском универзитету у Нев Јерсеи у Нев Јерсеи у Нев Јерсеи.
Већина људи који користе АИ за науку чине садржај да омогуће програмерима АИ алата да процене њихову корисност користећи сопствене критеријуме. То је попут пуштања фармацеутских компанија да одлуче да ли њихов лек треба да иде на тржиште, каже МцГреиви. „Исти људи који оцењују наступ АИ модела такође имају користи од тих процена“, каже он. То значи да, чак и ако истраживање није намерно лажно, то може бити пристрасно.

Како АИ преобликова науку и друштво
Лорена Барба, механички и ваздухопловни инжењер у Универзитету Георге Васхингтон у Васхингтону ДЦ, има сличну перспективу. Наука пати због „лоше транспарентности, сјајном ограничењем, крвним неуспехом, прекомерализацијом, непажљима података, непажљима података, у покушајима да ставе АИ у поставке у стварном свету, јер је она ставила у разговору на 2023. на платформи напредне научне рачунарске конференције у Давосу, Швајцарска.
Властито поље Барбе је динамика течности – која укључује проучавање проблема као што је изравнавање протока ваздуха преко крила авиона за побољшање ефикасности горива. Ради то укључује решавање парцијалних диференцијалних једначина (ПДЕ), али то није директно: већина ПДЕ се не може решити нумеричком анализом. Уместо тога, решења се морају приближити процесом који је сличан (стручно вођено) суђењу и грешци.
Математички алати који постижу да су то познати као стандардни решетки. Иако су релативно ефикасни, захтевају и значајне рачунарске ресурсе. Зато многи људи у динамици течности надају се да ће све посебно приступи машинама у учењу – могу им помоћи да учине више са мање ресурса.
Машинско учење је облик АИ који је у последњих пет година видео највише напретка – углавном због доступности података о обуци. Машинско учење укључује храњење података у алгоритам који тражи обрасце или предвиђа предвиђања. Параметри алгоритама могу се подесити да оптимизирају корисност предвиђања.
Теоретски, машинско учење могло би да пружи решења за брже и користећи мање рачунарских ресурса од конвенционалних метода. Проблем је у томе ако не можете да верујете да су мерила која се користе за процену перформанси корисна или поуздана, како можете да верујете излазу модела које потврђују?

Ницк МцГреиви је открило да су нека објављена побољшања АИ модела направила погрешне тврдње.Кредит: Ницхолас МцГрееви
МцГРеиви и његов колега Аммар Хаким, рачунарски физичар на Универзитету Принцетон, спровели су анализу објављених „побољшања“ стандардних решења и утврдила да је 79% радова које су проучавали дале проблематичне захтеве2. Велики део то везе са вредновањем против онога што изразе слабе основне линије. Ово може доћи из неправедних поређења: машинско учење за ПДЕ могао би се посматрати као ефикасније у погледу рачунарских ресурса – краће време извођења, на пример – од стандардног решавања. Али уколико решења нема сличну тачност, поређење је бесмислено. Истраживачи сугеришу да се поређења морају извршити на једнаку тачност или једнак временски време.
Други извор слабог вредновања упоређује АИ апликацију са не-аи нумеричким методама које су релативно неефикасне. На пример, на пример, научник података Сифан Ванг, који је сада на Универзитету Иале у Новом Хавену, Цоннецтицуту и рачунарском научнику Париз Пердикарис на Универзитету у Пенсилванији, тврдио је да је њихов решивач заснован на машини за различито класе диференцијалних једначина у поређењу са конвенционалним нумеричким решантима, на пример.3. Али као Цхрис Рацкауцкас, рачунарског научника на Массацхусеттс Институту за технологију у Цамбридгеу, наведен је у видео снимак са најсавременијим нумеричким решењима, од којих су некима могли да ураде посао 7000 пута брже – само на стандардним преносама.

Спремни или не, АИ долази на научно образовање – а студенти имају мишљења
„Бити фер према (Пердикарис), након што сам то истакао, уредили су свој рад“, каже Рацкауцкас. Међутим, додаје, оригинални папир је једина верзија која је доступна без плаћања и тако још увек и даље већа нада у вези са обећањем АИ-а у овој области.
Постоји много таквих погрешних тврдњи, МцГреиви упозорава. Научна литература је „није поуздан извор за процену успеха машинског учења на решавању ПДЕ“, каже он. У ствари, и даље није уговорњен да учење машине има било шта да понуди у овој области. „У ПДЕ истраживању, машинско учење је било и остаје решење које тражи проблем“, каже он.
Јоханнес Брандстеттер, истраживач машинског учења на Универзитету Јоханнес Кеплер у Линзу, Аустрији и суоснивача АИ-а Физицс СИМУЦИЈАЛНОГ РАСПОЛОЖИВАЧА ЗАВРШЕНА ЕММИ АИ, је оптимистичнији. Указује на критичку процену конкуренције предвиђања структуре (ЦАСП) која је омогућила учење машина да помогне у предвиђању 3Д протеинских структура из њихових аминокиселих секвенци4.