
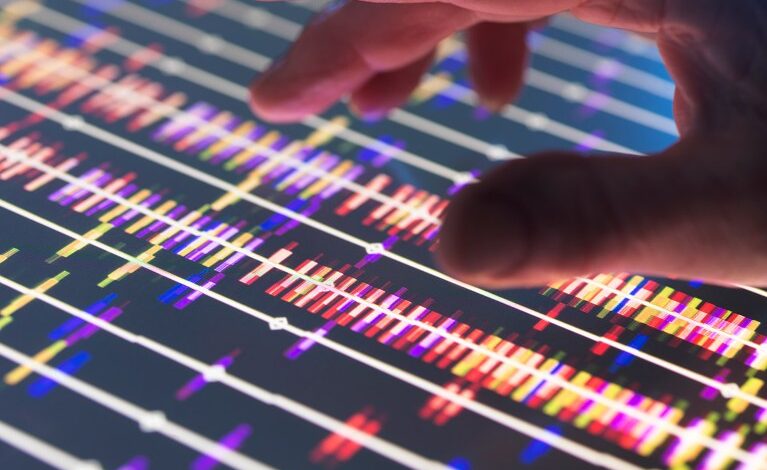

Индекси програма и огромне архиве ДНК, РНА и протеинских секвенци. Научници могу да претражују архиве и у трагу биолошке контексте у великим подацима.КРЕДИТ: Андрев Броокес / Цоннецт Имагес / Сциенце Фото библиотека
Интернет има Гоогле. Сада је биологија има престану. Детаљан данас у Природа1претраживач може брзо проћи кроз запањујуће количине биолошких података смештених у јавним спремиштима.
„То је огромно достигнуће“, каже Раиан Цхикхи, истраживач биокомпута на Пастеур Институту у Паризу. „Они постављају нови стандард“ за анализу сировских биолошких података – укључујући ДНК, РНА и протеин секвенце – из база података које могу садржати милион милијарди и писаћих слова у износу од „петабаза“ информација, више уноса од свих веб страница у Гоогле-овој веб страници у Гоогле-овом веб страницу.
Иако је пребацивање метара означено као „Гоогле за ДНК“, Цхикхи се личи алат за претраживач за ИоуТубе, јер су задаци рачунарски захтевни. На исти начин на који ИоуТубе претражује сваки видео снимак који функционише, рецимо, црвене балоне чак и када се оне кључне речи не појаве у наслову, ознакама или опису, могу да открију генетски обрасце скривене дубоко у ексансивним секторима података без потребе да се они обрасци треба унапред означити.
„Омогућује ствари које се не могу учинити ни на који други начин“, каже Цхикхи.

Смарт Софтваре Унаследа у регулацију гена у ћелијама
Индексирање животне библиотеке
Мотивација која стоји иза метара била је да се реши проблем приступачности у секвенцирању скупова података. Величина ових складишта порасла је на блистеринг темпо у последњих неколико деценија, али овај раст је представио изазове научницима који користе податке које садрже. Реаксна секвенцизација је фрагментирана, бучна и превише бројна која ће директно претражити. „Обим података, парадоксално је да је главни инхибитор нас заправо користили податке“, каже Артем Бабаиан, рачунарски биолог на Универзитету у Торонту у Канади.
Према речима студије, Андре Кахлес, биоинформатијаца на швајцарском федералном технологији (ЕТХ) Цирих-у, претерано је помоћи истраживачима да постављају биолошка питања спремишта, као што је архива за читање секвенце (СРА), јавна база података која садржи више од 100 милиона милијарди ДНК слово2
Они су се решили са проблемом употребом математичких ‘графичких’ графикона који су повезани преклапајући ДНК фрагмента заједно, слично као што су реченице које деле исте речи које се баве у књизи.
Истраживачи су интегрисани подаци из седам јавно финансираних складишта података, стварајући 18,8 милиона јединствених сетова ДНК и РНА секвенце и 210 милијарди секвенце аминокиселих сета у свим прикупљањима живота – укључујући вирусе, бактерије, гљивице, биљке и животиње, укључујући људе, бактерије, гљивице, биљке и животиње. Такође су развили претраживач за ове секвенце, у којима корисници користе текстуалне упутства за претрагу ових интегрисаних архива сирових података.
„То је потпуно нов начин да комуницирамо са овим тијелом података“, каже Кахлес. „Компримирана је, али доступна у муху.“
Огромна база података протеина која је спала алфафал и биологију АИ револуцију
Да бисте демонстрирали корисност пута, студијски аутори користили су га за скенирање 241,384 узорака за микробиоме људског црева за генетски индикатори антибиотске отпорности широм света, зграде на ранији који је користио ранију верзију алата за праћење гена отпорности на дрогу у бактеријским системима у бакционим системима у бакционим системима у бакционим системима у бакционим системима.3. Аутори кажу да су анализирали за око сат времена на врхунским путем.



