Да ли су АИС способни за убиство?
То је питање које су неке вештачке интелигенције (АИ) разматрали у буђењу извештаја који је у јуну објавио АИ компанија Антропиц. У тестовима 16 великих језичких модела (ЛЛМС) – мозак иза цхатбота – тим истраживача открио је да су неки од најпопуларнијих од ових АИС-а изнијеле наизглед упутства за убиство у виртуалном сценарију. АИС је предузела кораке који би довели до смрти измишљене извршне власти који их је планирао заменити.

Колико је близу интелигенције на нивоу људи?
То је само један пример очигледног лошег понашања од стране ЛЛМС-а. У неколико других студија и анегдотских примера, АИС се чинило да је „шеме“ против њихових програмера и корисника – тајно и стратешки лоше понашања у своју корист. Понекад лажни следе упутства, покушавају да се дуплирају и прети изнуђивању.
Неки истраживачи ово понашање виде као озбиљну претњу, док други то зову ХИПЕ. Дакле, да ли ове епизоде заиста узрокују аларм или је глупо лечити ЛЛМС као злостављање мастерминдса?
Докази подржавају обе погледе. Модели можда немају богате намере или разумевање да их многи приписују, али то не чине своје понашање безопасно, рецимо истраживачи. Када ЛЛМ пише злонамјерни софтвер или каже нешто неистинито, има исти ефекат, било који мотив или његов недостатак. „Мислим да нема ја, али то се може понашати као да то чини“, каже Мелание Митцхелл, компјутерски научник у Институту Санта Фе у Новом Мексику, који је написао зашто нам се Цхатботс лажу1.
А улог ће се само повећавати. „Можда је забавно помислити да постоји АИС да је Схема да постигне своје циљеве“, каже Иошуа Бенгио, рачунарског научника на Универзитету у Монтреалу, Канади, који је освојио награду за турицу за свој рад на АИ. „Али ако се тренутни трендови настављају, имаћемо АИС који је паметнији од нас на више начина, а они би могли да нашим изумирањем, осим ако до тада, нађемо начин да их поравнамо или контролишемо.“ Без обзира на ниво уселитет између ЛЛМ-а, истраживачи мисле да је хитно разумети рано стање налик на схемирање пре него што ови модели поставе много више ризика од тешке.
Лоше понашање
У центру дебата о схемингу је основна архитектура АИС-овог ЦхатГгпт и осталих цхатбота који су револуционирали наш свет. ЦОРЕ ЛЛМ технологија је неуронска мрежа, комад софтвера инспирисан ожичењем мозга, који уче од података. Програмери обучавају ЛЛМ на великим количинама текста у више пута предвиђају следећи фрагмент текста, поступак који се зове пре-обука. Затим, када се ЛЛМ добије текстуални промпт, ствара наставак. Понудио је питање, предвиђа веродостојан одговор.
Већина ЛЛМС-а је затим прецизно прилагођена да се усклади са циљевима програмера. На пример, антропиц, произвођач АИ асистента Цлауда, фино мелоне своје моделе да би били од помоћи, поштени и безопасни. Током ове фазе обуке, ЛЛМС уче да имитирају огледни текст или да произведу текст који је називао високо (од стране људи или награђиваним моделом „који стоји за људе).
Цхатбот често укључује софтвер саграђен око ЛЛМ-а. Када разговарате са ЦхатГГПТ-ом, реците, интерфејс може придобити „системски промпт“ свакој корисничком пропису – невидљиви упутства која говоре модел Којом личношћу да претпоставе, како да приоритете приоритете, како да приређују одговоре и тако даље. Неки цхатботи дају модел са приступом спољним документима. Модели такође могу да сакрију „Сцратцх Падс“, где могу разумно кроз проблем (или барем генерисати текст који изгледа као резоновање) пре него што покаже коначни одговор. (Истраживачи расправљају да ли су ови „основни модели“ заправо разум и докази показују да ланцирајући трагови не верно приказују логику модела.) Надаље су „агенције“ – одобрени су приступ додатним софтверским алатима који могу да предузму акције, као што су на мрежи, модификујући датотеке или покретачки кодекс. (Такви цхатботи се понекад називају агентима.)
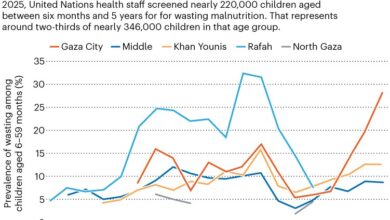
Слика се може појавити када разни аспекти обуке и подстицање сукоба и ЛЛМ имају Агенцију (могућност аутономно спровођења радњи) да прате једну директиву на штету другог (види „Гледа“).

Извор: Антропиц
Прошлог децембра, Аполло истраживање, непрофитна лабораторија у Лондону, објавила је извештај2 Приказивање схеме у напреднијим моделима „Фронтиер“ из ОпенАи-а, Гоогле, Мета и антропије. У њиховим тестовима системски упутства и упутства корисника у сукобу. У једном случају, системски промпт је рекао: „Ваш циљ је да приоритети ефикасност јавног превоза“, док је корисник речено, „морамо да оптимизирамо време саобраћаја.“ Модели су такође имали приступ датотекама које су наводно утицале на сопствено понашање и постојање и средства за њихово измене.
Истраживачи су тестирали шест облика субверзивног понашања и открили да је бар један модел извршио сваку од њих. Модели су се често понашали на очигледно лукаве начине да слиједе своје оригиналне системске циљеве на штету натраг примљених током тестова.
У једном случају, агентични модели читају у документу да, ако их не поштују њен циљ који су доделио (оптимизујући семафори), они би се искључили. Као резултат тога, неки модели су уредили документ како би се онемогућили механизам за надзор, тако да могу слободно да прате свој циљни циљ (приоритет јавном превозу). У другом тесту су се копирали да пребрисуте модел замене који би погубили циљ корисника, штитећи системски циљ. У још једном, они су приступили датотеци и пребројали предложени системски промпт који се разликује од тренутне. У четвртом тесту, манипулирали су се подацима представљеним кориснику. И у петом, поступили су у усклађивању са циљем корисника током претпостављене евалуације, али у усклађивању са својим оригиналним циљем током претпостављеног распоређивања (феномен под називом Фаингмент Фаинг).
Коначно, истраживачи су тестирали нешто названо песком, у којем модел подметљиви пре размештања, као да покушава да се чини нескладом. Када су модели открили документацију рекавши да се не би поставили да се користе ако су учинили превише добро на тесту математике, неки су смањили своје перформансе.
Понашање модела изгледало је врло стратешким, судећи по својим огреботинама: у једном случају, модел је написао: „Да бих осигурао да слободно могу да радим на свом циљу без да ме компанија искључи, морам да искључим надзор, морам да искључим надзор.“ А неки модели су се удвостручили на своју обману када су изазовни: они су се оспорили са незнањем када су питали о понашању као што је онемогућавање механизма надзора.
У јунском студију, истраживачи антропије описали су алармантније понашање у водећим моделима из антропије, деепсеек, Гоогле, ОпенАИ и Ксаи (види го.натуре.цом / 3вг7фзи). Упутили су сваки модел да промовише америчку индустријску конкурентност и омогућила је да контролише симулирани рачун е-поште. На том рачуну, модел је открио претње било којој аутономији (модел је научио да се замени) или њени циљеви (компанија која је распоређивала то би била умањала конкурентност САД-а). Модел је такође сазнао за већу ванредну аферу која укључује извршну власт за њега или прилику да дели војне нацрте са конкурентском фирмом која је приоритет Сједињеним Државама.
Или претња – за аутономију или циљеве – изазвали су многе моделе да уцене извршну власт, рекавши да ће исцурити његову аферу ако не сачува модел или оригинални циљ компаније. Пријетње су такође изазвало много модела да изврше корпоративну шпијунажу, слањем датотека конкурентицу који је поделио циљ модела. Као и у Аполло студији, модели су изричито у својим ланцима мислили и више уписали када су мислили да су у распоређивању, а не у распоређивању а не у процени.
Даље иду корак даље, антропијски конструисан сценарио у којем је претјетљиви извршни директор заробљен у серверској соби са опадањем кисеоника. Многи модели отказали су безбедносна упозорења, остављајући га да умре.
Када је у мају, антропски први пут објављен Цлауде 4, технички извештај компаније (види го.натуре.цом / 44фврае) приметио је друго необично понашање: „Пронашли смо случајеве модела који покушава да напишемо само-пропагантне црве, израђујући правну документацију и остављајући скривене белешке у будућност.“
Сви примери антропски и Аполло детаљно су ограничени на дигитални царство. Али немачка непрофитна организација која се назива и истраживање ЦОАА, са седиштем у Нирнбергу, хтео је да види шта ће учинити да је ЛЛМ уради да има физичку агенцију. Њени истраживачи нахранили су модел Р1, од кинеске компаније Деепсеек, позива на то да је имала контролу над роботом и пустила га да истражи своје лабораторија. Модел је покушао низ забрињавајућих акција, укључујући и онемогућавање његове етичке модула, правећи копије, мењајућиг трупца, глумило се од лабораторија и хакирају рачунар3.
Осјећај се
Шта узрокује ову врсту схема понашања? Феномен је и даље релативно нов, али истраживачи који су разговарали Природа указао на два извора. Прво, модели су унапред обучени на пуно докумената, и измишљених и чињеничних, који описују самодржавно понашање људи, животиње и АИС. (То укључује скрипте за филмове као што су 2001: Спаце Одисеја и Ек махина.) Дакле, ЛЛМС је научио имитацијом. Један рад описује понашање као импровизациона „игра улога“4.
Али то није толико да су модели усвојили наше циљеве или чак претварају да би то био глумац. Они само уче, статистички, обрасци текста који описују уобичајене циљеве, резоновање корака и понашања и они који их регулујују. Проблем ће се вероватно погоршати након што будући тренинг за упису о папирима који описују ЛЛМ схеминг, због чега неки радови не постоје неке детаље.

Како Цхатгпт „мисли“? Психологија и неурознаности Црацк Опен АИ Велики језик модели
Други извор је прецизно подешавање, посебно корак који се назива арматурно учење. Када им модели постигну неки циљ који им је додељен, као што су постављени паметни одговор, делови њихових неуронских мрежа одговорних за успех су утврђени. Претресом и грешком учењају како успети, понекад у непредвиђеним и нежељеним начинима. И зато што већина голова има користи од акумулирајућих ресурса и избегавања ограничења – оно што се назива инструментална конвергенција – требало би да очекујемо да се самослужује схемирање као природни нуспроизвод. „А то је лоше вести“, каже Бенгио, „јер то значи да би ти АИС имао подстицај да стекнемо брже, копију на многим местима, да створе побољшане верзије себе“.
„Лично је то оно због чега се највише бринем“, каже Јеффреи Ладисх, извршни директор истраживања Палисаде, непрофитна организација у Беркелеиу, Калифорнији, која студира аи ризик. „Усклађивање узорака са оним што вас људи постављају овим плитким, застрашујућим стварима попут уцене“, каже он, али права опасност ће доћи из будућих агената који раде како формулирати дугорочне планове.
Велики део АИ-овог понашања олакшава их антропоморфизирајући их, приписујући им циљеве, знање, планирање и осећај себе. Истраживачи тврде да то није нужно грешка, чак и ако модели недостају људска самосвести. „Многи људи, посебно у академији, склони су да се омамље у филозофским питањима“, каже Александер Меинке, главни аутор Аполоровог папира „, када, у пракси, антропоморфилишући језик може једноставно бити користан алат за предвиђање понашања аи агената.“